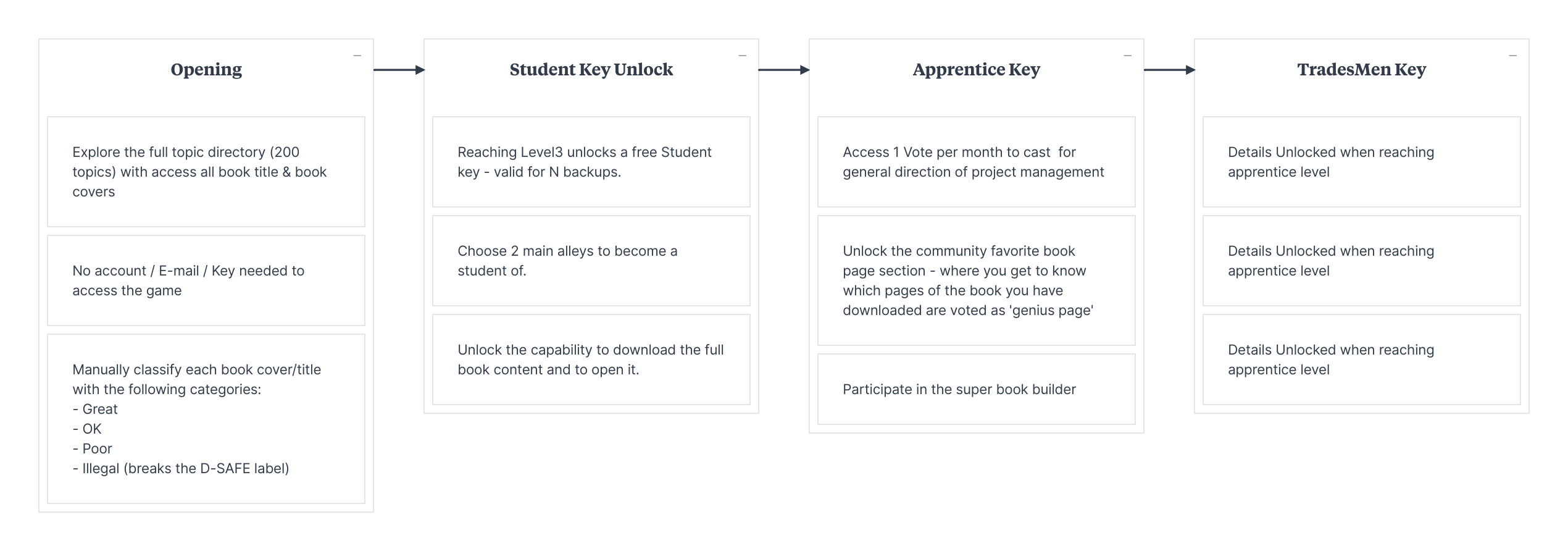
Good day!
Great question, and thank you for helping me being very specific concerning A11Y design.
The product will have high contrast view by default. Right now only the dark theme is implemented, but It is planned to have a light theme implemented later on.
I am a strong believer that following A11Y compliant design is great for people with vision impairment, but also for those who have perfect vision. Having a clear high contrast design helps the reader to focus longer, and it makes it easier for them to access the information they are looking for.
Many of the PDF books I have are old books printed early last century. Some are as old as the 1800s. At that time, there was no computers, and therefor, the PDF is the result of concatenated scanned image that contains no information related to the actual text content.
With today’s tech, It is still possible to implement text-to-speech functionality for those books - it involves the usage of OCR (Optical character recognition ) as an additional step in the processing of the PDF.
Version 0.7.* (The desktop app) is using the following process:
1 - Download the PDF from Arweave
2 - Preprocess the PDF and extract every page as a JPG image - using the MuPDF WASM that can be found here
3 - Store all images on the local file system.
With MuPDF, it is also possible to extract the text - when the data is available.
It is possible to then process this text with a text to speech library.
When not available , another step would be to process each image with an OCR, such as tesseract . I haven’t looked into it, so I don’t know about the quality of the result.
High contrast mode is by default - but I could also add a vision impairement mode too, that would process each image to increase contrast using some image processing WASM step.
To summarize, a possible approach could be:
1 - Download the PDF from Arweave
2 - Preprocess the PDF and extract every page as a JPG image
3 - Does the user wants high contrast mode + text2speech ?
if YES, increase the image contrast with image post-processing libraries.
Does the PDF book contains text as vector?
if YES, extract the information alongside the image, and store it into the user’s local storage
if NO, add an extra Web-Worker to process OCR, and store the processed result on local storage
Find a nice open source TextToSpeech library, and use it for reading the book content - in sync with the PDF viewer.
I believe this approach could become an advanced open source PDF reader library by itself ( sponsored by the D-SAFE World library initiative ).